
この記事では、Pythonで『UnicodeEncodeError: 'shift_jis' codec can't encode character』と出たときの、解決方法をお伝えします。
このエラーは、Webスクレイピングで取得した文字列を、to_csv()でファイルに保存するときに発生。
いろいろ試した結果、to_csv()のencodingの引数を、shift-jis ⇒ utf-8 へ変更することで解決できました。
普段あまり文字コードを意識しなかったので、はまってしまいました。文字コードの知識は、「日本語」を扱う場合は特に重要ですね。
もくじ
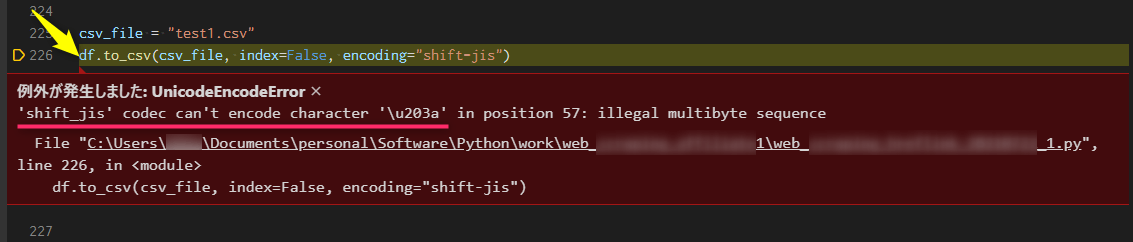
エラーログの画面「'shift_jis' codec can't encode character '\u203a'」
ピンクの下線が、エラーログ「'shift_jis' codec can't encode character '\u203a'」。
「Shift-JISでは、\u203a の文字コードを変換できない!」と言っています。
黄色の矢印が、実行コマンド「pandasのto_csv()関数」です。encodingに文字コード「shift-jis」を指定すると、例外が発生!
UnicodeEncodeError(Visual Studio Code)
原因は、「Shift-JIS」にはない「文字コード」だったから
原因はエラーログのとおり、「Shift-JISでは、\u203a の文字コードを変換できなかった。」からです。
そもそも変換できなかった大元の原因は、Shift-JIS(日本語の文字コード)の中に、対応する文字コードがそもそもなかったからです。
エラーログの「\u203a」って、どんな文字でしょうか?
下図は、Unicode一覧表です。203a に対応する文字は、左端の 2030の行(ヨコ方向)と A列(タテ方向)が交差する箇所です。
\u203a(Unicodeの文字コード)は、不等号「>」と似ていますが、別の文字です!
(\u は、ユニコードのエスケープシーケンス)
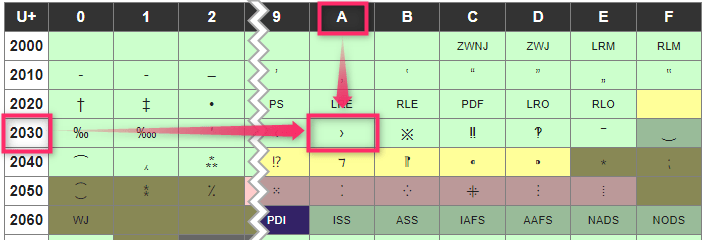
出典:Wikipedia Unicode一覧 2000-2FFF >>https://ja.wikipedia.org/wiki/Unicode一覧_2000-2FFF
クリエイティブ・コモンズ 表示 - 継承 4.0 国際 ライセンスの下に提供されています。

「Shift-JIS」(日本語の文字コード)には、\u203a に対応する文字はないな~。
Shift-JISに変換できずにエラーになったのも納得。
上記の症状は、Webスクレイピングで読み込んだテキストの文字コードと、ファイル保存時の文字コードの種類が違うので、文字コード変換の失敗時に出た例外です。
対処としては、スクレイピングしたテキストの文字コードは「UTF-8」なので、ファイル保存時も、同じ「UTF-8」にするのが無難ですね。
「文字コード」を Shift-JIS ⇒ UTF-8へ変更して、解決!
解決方法は、pandasの「to_csv()関数」 の引数encoding(文字コード)を、shift-jis ⇒ utf-8 へ変更する、です。
encodingは、出力ファイルの文字コードを指定する引数です。
変更前
encodingに、shift-jis を指定。
df.to_csv(csv_file, index=False, encoding='shift-jis')
変更後
encodingに、utf-8 を指定。
df.to_csv(csv_file, index=False, encoding='utf-8')
「errors='ignore'」は、情報が欠落する!
下記のように、「errors='ignore'」を指定すると、文字コード変換の失敗は無視されるので、UnicodeEncodeError は発生しません。
df.to_csv(csv_file, index=False, errors='ignore')
見かけ上、エラーが発生しないだけで、「Shift-JIS(日本語の文字コード)へ変換ができなかった事実」は解消できず残ったままです。
変換できなかった文字コードの部分は、どうなるのでしょうか?
この文字の箇所の情報は欠落して、ファイルに保存されます!
運用システムによって、情報の欠落が許されない場合もあると思います。
「errors='ignore'」を使うかどうかは、「情報が失われ可能性がある」ってリスクをふまえて使うかどうか判断した方が安全ですね。
「errors='ignore'」でファイル保存 ⇒ 文字が消えた!【検証結果】
to_csv() の「errors='ignore'」指定”なし”と”あり”で、UnicodeEncodeErrorの文字がどうなるか? 保存したファイルの中身を検証しました。
右の図に注目してください。予想とおり、本来あるべき文字(情報)がなくなっています!
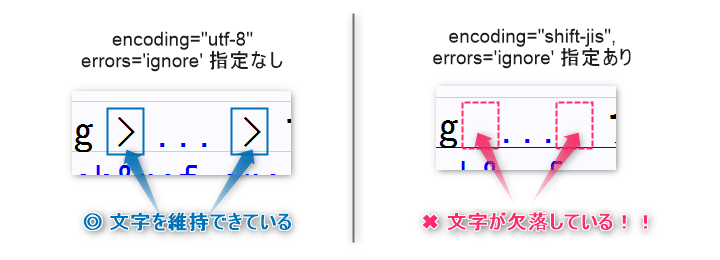
情報が欠落しないように、今回の「修正案」では、「errors='ignore'」を使わず、「encoding='utf-8'」で文字コードに UTF-8 を指定。
「文字コード」についておさらい!
まとめ
この記事では、Pythonで「UnicodeEncodeError. 'shift_jis' codec can't encode character」と出たときの、解決方法をお伝えしました。
Pythonの標準文字コード(バージョン3.x以降)は UTF-8ですが、普段あまり文字コードを意識しなかったので、はまってしまいました。
文字コードの知識は、「日本語」を扱う場合は、特に重要になると思います。
以上、参考になれば幸いです。